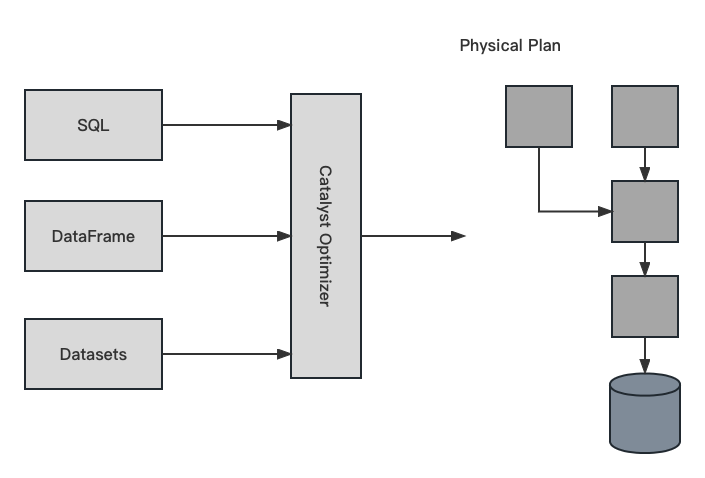
1. 执行流程概述(Overview)
- 写 DataFrame/Dataset/SQL 代码;
- Spark 会将有效的代码转成逻辑执行计划;
- Spark 会将逻辑执行计划转成物理执行计划,期间也会检查优化;
- Spark 会在集群上执行物理执行计划(RDD操作)。
1.1 Catalyst Optimizer
Optimizer 是整个 Catalyst 的核心,优化器主要分为基于规则的优化(RBO)和基于代价的优化(CBO)两种。
1.2 逻辑执行计划(Logical Planning)
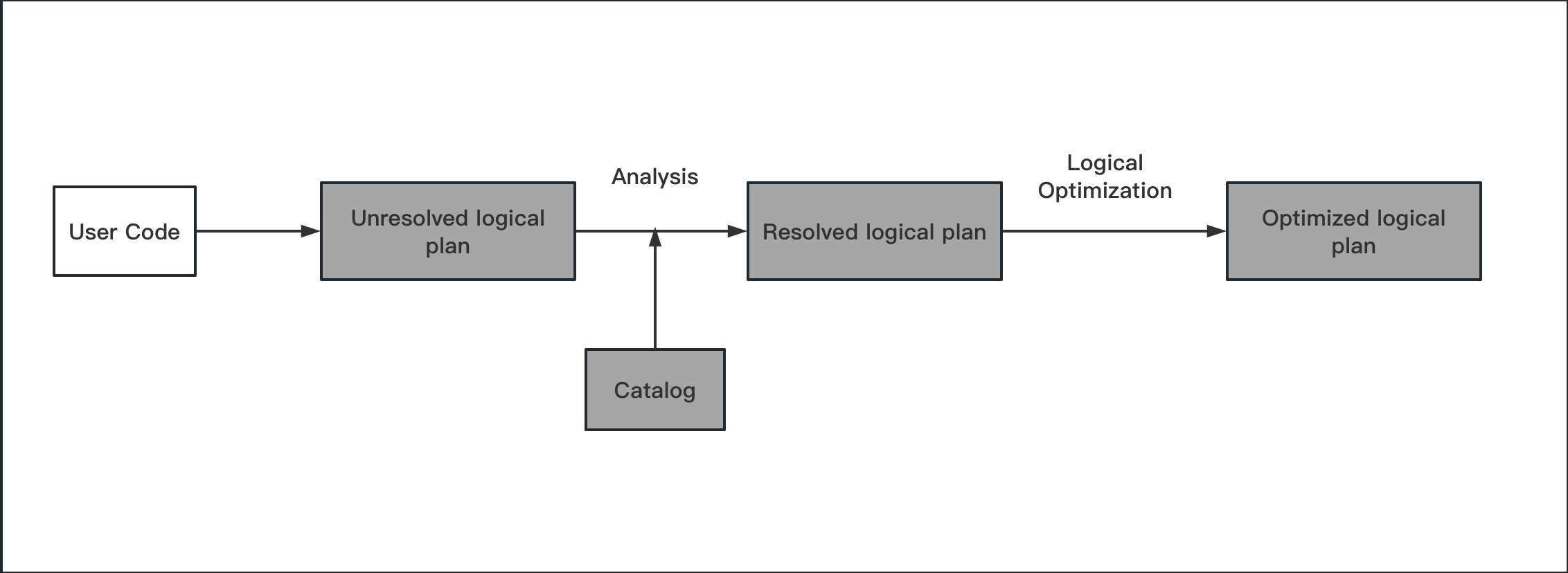
逻辑执行计划是一个抽象语法树,它描述了执行计划的逻辑。逻辑执行计划是一个无状态的转换,它不会考虑数据的分布,也不会考虑执行计划的成本。逻辑执行计划的主要目的是为了将用户的查询转换成一组可以被优化的逻辑操作;
- unresolved logical plan:未解析的逻辑执行计划,这个过程主要是判断用户输入的 SQL 语句是否符合规范,此阶段不会对表或者字段进行检查;
- resolved logical plan:已解析的逻辑执行计划,这个过程主要是通过 Catalog(基本的元数据信息,如表的 schema 信息和基本函数信息) 对表或者字段进行检查,如果表或者字段不存在,会抛出异常;
- optimized logical plan:优化后的逻辑执行计划。通过 Catalyst Optimizer 对逻辑执行计划进行优化,这里是基于规则的优化。
1.2.1 基于规则的优化(RBO)
这部分的优化规则大部分都是启发式规则,也就是说,这些规则都是基于经验的,而不是基于代价的,RBO不考虑具体查询的数据分布和查询成本,而是基于一组规则来生成查询计划。
- 谓词下推(Pushing Down Predicates): 将过滤条件尽可能的下推到底层,最好是数据源,这样可以减少数据的读取量,提高效率。以 join 操作为例,海量数据的关联操作下,先过滤掉不符合条件的数据,再进行关联操作,可以大大减少参与 join 操作的表的大小,降低耗时。
- 常量累加(Constant Folding): 这个阶段可以把一些表达式事先计算好,比如 1+1,可以直接计算出结果等于 2,这样可以减少计算量,提高效率。
- 列值裁剪(Column Pruning): 当查询的表有很多个字段,但是每次查询只需要其中的几个字段,那么就可以在这个阶段将不需要的字段裁剪掉,这样可以减少扫描的数据量,提高效率。
1.2.2 The structured API logical planning process
1.3 物理执行计划(Physical Planning / Spark Plan)
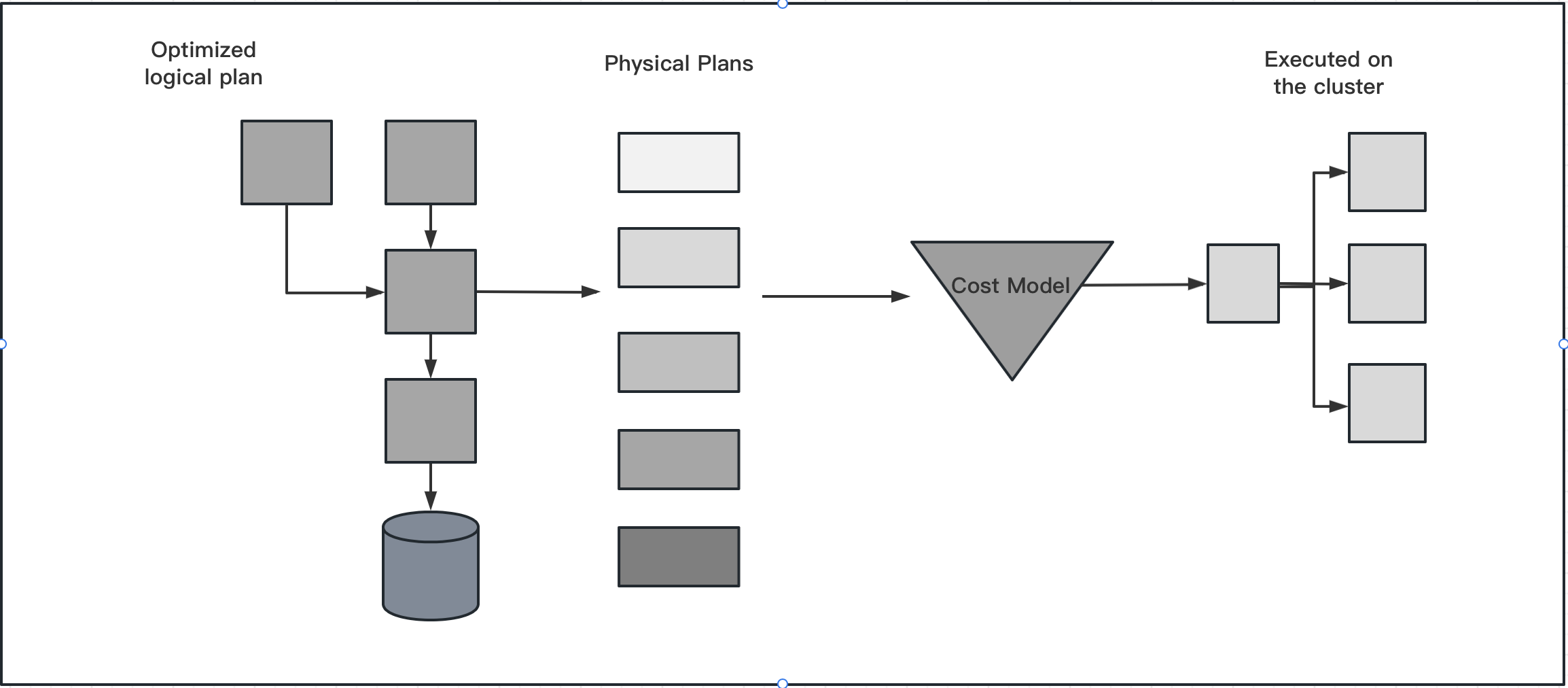
物理执行计划是一个 RDD 操作的序列,它描述了如何在分布式环境中执行逻辑执行计划。物理执行计划是一个有状态的转换,它会考虑数据的分布和执行计划的成本。物理执行计划的主要目的是为了将逻辑执行计划转换成一组可以被 Spark 执行的物理操作。这也可能是为什么 Spark 也会被称为编译器,它基于 DataFrames/Datasets/SQL 查询并将他们转换成了一组 RDD 操作。
- 将逻辑执行计划进行转换,生成多个可以执行的物理执行计划;
- 通过 cost model 计算每个物理执行计划的代价,选择代价最小的物理执行计划作为最优物理执行计划。
1.3.1 基于代价的优化(CBO)
CBO是一种基于成本的优化方法,它利用实时统计信息来评估查询的各个可选执行计划的成本,并选择成本最低的执行计划作为最优计划。因为CBO需要实时统计信息和成本模型的支持,需要额外的成本计算和结构维护,因此可能会增加查询优化的复杂性和计算成本。
根据 cost model 计算每个 physical plan 的代价,包括 IO 成本、CPU 成本等,选择代价最小的 physical plan 作为最优物理执行计划。
1.3.2 The physical planning process
1.4 执行物理计划(Execution)
Spark 根据最优的物理执行计划,生成 Java 字节码,将 SQL 转化为 DAG,以 RDD 形式进行操作。
2. 总结
Spark SQL 到 RDD 中间经过了一个优化器(Catalyst),它是 Spark SQL 的核心,是针对 Spark SQL 语句执行过程中的查询优化框架,基于 Scala 函数式编程结构。
3. 参考资料
- Spark The Definitive Guide
- https://www.cnblogs.com/itlz/p/16174068.html