1. 一致性检查点#
1.1 概念#
一种由 Flink 自动执行的快照,其目的是能够从故障中恢复。Checkpoints 可以是增量的,并为快速恢复进行了优化。
检查点是 Flink 容错机制的核心。这里所谓的检查,其实是针对故障恢复的结果而言的:故障恢复之后继续处理的结果,应该和故障发生之前完全一致,我们需要检查结果的正确性。所以,有时候又会把 checkpoint 称为一致性检查点。
1.2 前提条件#
Flink 的 checkpoint 机制会和持久化存储进行交互,读写流与状态。一般需要:
- 一个能够回放一段时间内数据的持久化数据源,例如持久化消息队列(例如 Apache Kafka、RabbitMQ、 Amazon Kinesis、 Google PubSub 等)或文件系统(例如 HDFS、 S3、 GFS、 NFS、 Ceph 等)。
- 存放状态的持久化存储,通常为分布式文件系统(比如 HDFS、 S3、 GFS、 NFS、 Ceph 等)。
2. 从一致性检查点中恢复#
在流式应用执行过程中,Flink 会周期性地为应用状态生成检查点。一旦发生故障,Flink 会利用最新的检查点将应用状态恢复到某个一致性的点并重启处理进程。
Flink 故障恢复的过程需要 JobManager 参与。
这里需要注意的是,Flink 的检查点和恢复机制仅能重置流式应用内部的状态,这里与端到端的精准一次还是有区别的。
应用恢复需要经过 3 个步骤:
- 重启应用;
- 利用最新的检查点重置任务状态;
- 重放数据(Source 任务向外部数据源重新提交偏移量);
- 继续处理。
3. Flink 检查点算法#
当所有的任务都恰好处理完一个相同的输入数据的时候,将它们的状态保存下来。首先,这样避免了除状态之外其他额外信息的存储,提高了检查点保存的效率。其次,一个数据要么被所有任务完整地处理完,状态得到了保存;要么就是没处理完,状态全部没保存:这就相当于创建了一个事务(transaction)。
如果出现故障,我们恢复到之前保存的状态,故障正在处理的所有数据都需要重新处理;所以只需要让源任务向数据源重新提交偏移量(offset)、请求重放数据就可以了。这需要源任务可以把偏移量作为算子状态保存下来,而且外部数据源能够重置偏移量,比如 Kafka。
- 检查点分隔符(checkpoint barrier)
一种特殊的数据结构,专门用来触发检查点保存的时间点。当 Source 算子收到 JobManager 保存检查点的指令后,Source 任务可以在当前数据流中插入这个结构(barrier);之后所有的任务只要遇到它就开始对状态做持久化快照保存。由于数据流是保持顺序异常处理的,因此遇到这个标识就代表着之前的数据都处理完了,可以保存一个检查点;而在它之后的数据,引起的状态改变就不会体现在这个检查点中,而需要保存到下一个检查点。
每个检查点分隔符都会带有一个检查点编号,这样就把一条数据流从逻辑上分成了两个部分。
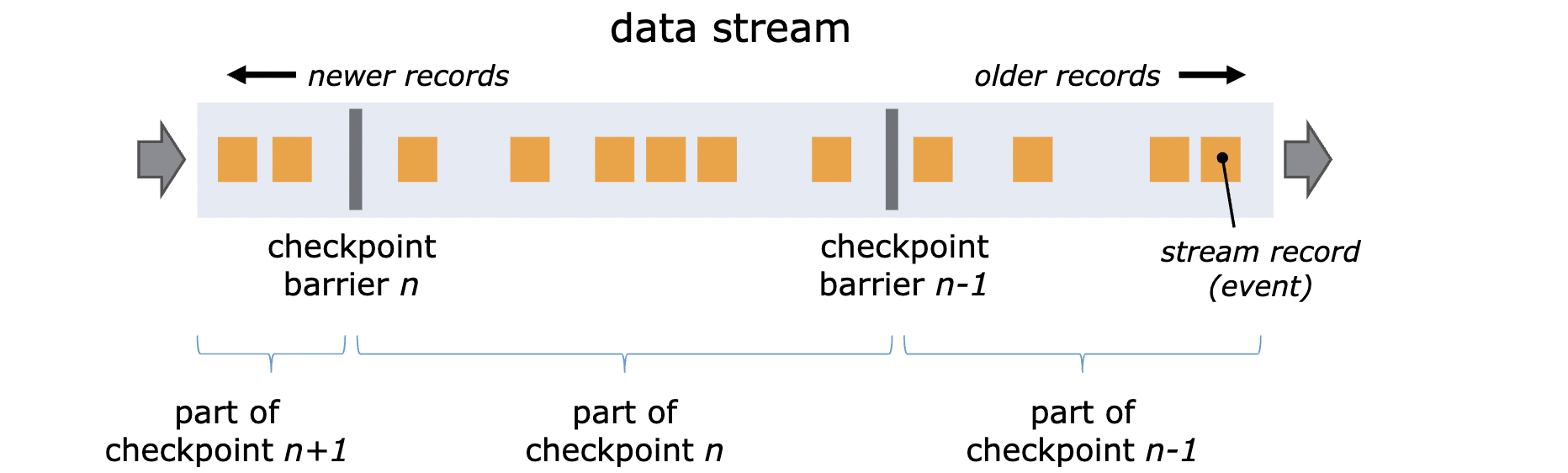
Flink 使用 Chandy-Lamport algorithm 算法的一种变体,称为异步 barrier 快照(asynchronous barrier snapshotting)。
算法的核心就是两个原则:当上游任务向多个并行的下游的任务发送 barrier 时,需要广播出去;而当多个上游任务向同一个下游任务传递 barrier 时,需要在下游任务执行“barrier 对齐”(barrier alignment)操作,也就是需要等到所有并行分区的 barrier 都到齐,才可以开始状态的保存。
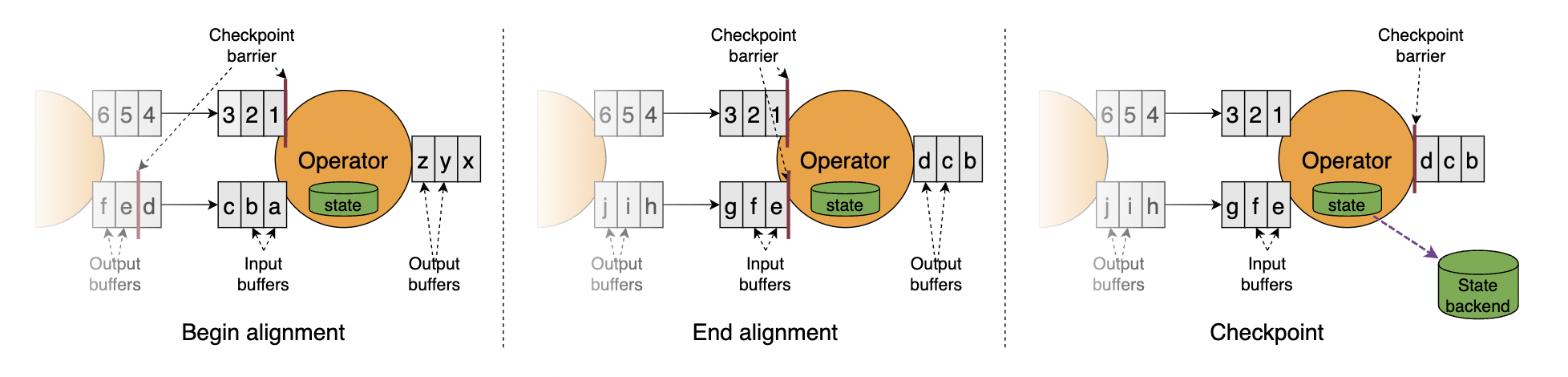
- 检查点的生成
- JobManager 发送指令,触发检查点的保存;Source 任务保存状态,插入分界线;
- Source 任务状态快照保存完成后,barrier 向下游传递;
- 向下游多个并行子任务广播 barrier,执行 barrier 对齐;
- barrier 对齐以后,保存状态到持久化存储;
- 先处理缓存数据,然后正常继续处理。
4. Flink 检查点配置#
默认情况下 checkpoint 是禁用的。通过调用 StreamExecutionEnvironment 的 enableCheckpointing(n) 来启用 checkpoint,里面的 n 是进行 checkpoint 的间隔,单位毫秒。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| public class CheckpointExample {
public static void main(String[] args) throws Exception {
// 创建上下文环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(1000);
// 高级选项:
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确认 checkpoints 之间的时间会进行 500 ms,这意味着有效检查点生成间隔至少为 500 ms
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 允许两个连续的 checkpoint 错误
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2);
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
// RETAIN_ON_CANCELLATION 在应用完全失败和显式取消时保留检查点
// DELETE_ON_CANCELLATION 只有在应用完全失败后才会保留检查点。如果应用被显式取消,则检查点会删除。
env.getCheckpointConfig().setExternalizedCheckpointCleanup(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 开启实验性的 unaligned checkpoints (非对齐检查点)。
env.getCheckpointConfig().enableUnalignedCheckpoints();
}
}
|
5. 检查点对性能的影响#
任务将其状态存入检查点的过程中,会处于阻塞状态,此时的输入会进入缓冲区。由于状态可能会很大,而且生成检查点需要把这些数据通过网络写入远程存储系统,该过程可能持续数秒,甚至数分钟。这对于一些延迟敏感的应用而言时间过久。
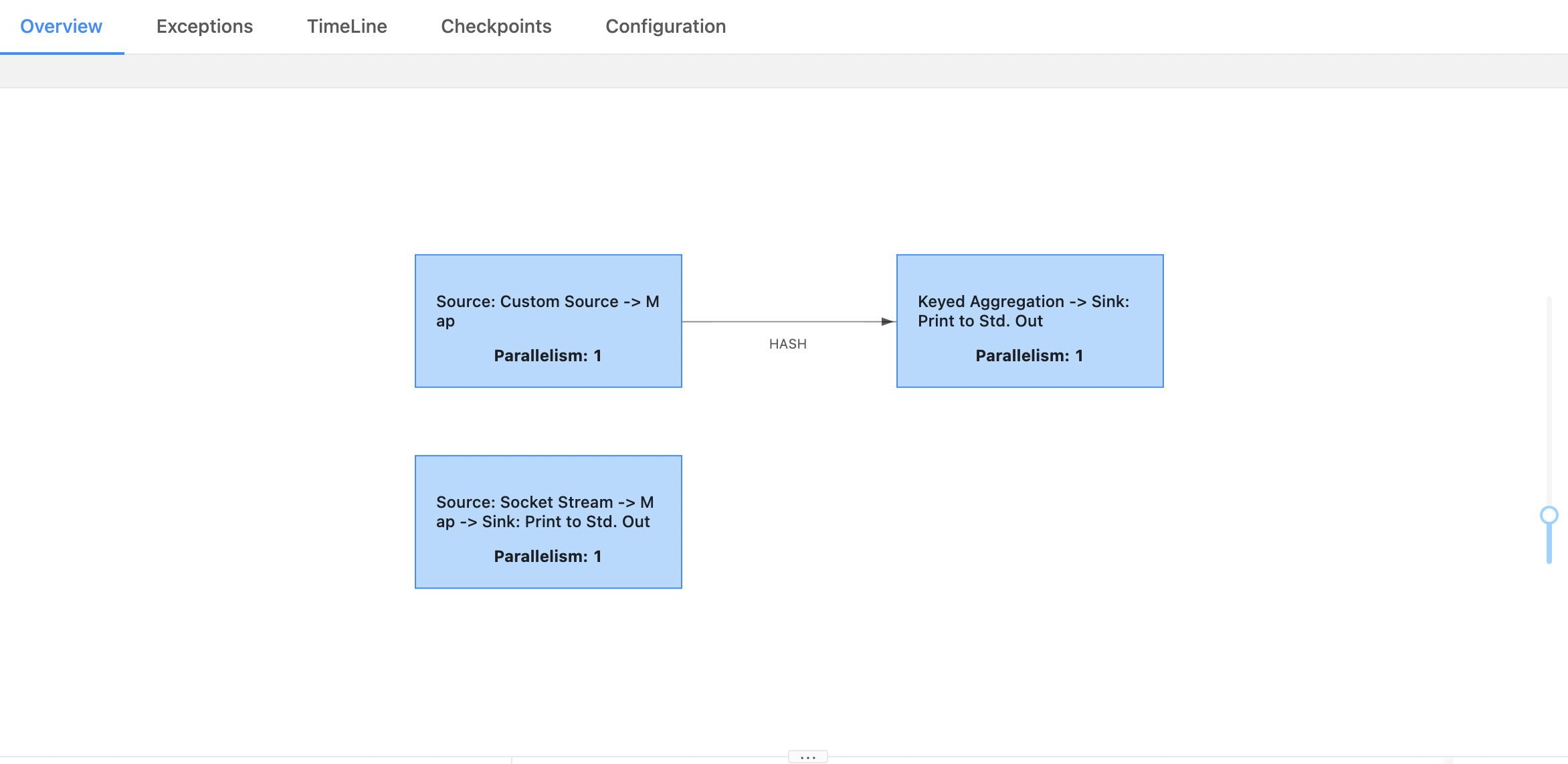
6. demo 演示#
1
2
3
4
5
6
7
| # 首先启动本地的 kafka 集群
./zookeeper-server-start.sh ../config/zookeeper.properties
./kafka-server-start.sh ../config/server.properties
# 创建 topic (副本的个数不能大于 broker 的个数)
./kafka-topics.sh --create --topic flink-source --partitions 3 --zookeeper localhost:2181 --replication-factor 1
# 启动生产者模拟发送消息
./kafka-console-producer.sh --broker-list localhost:9092 --topic flink-source
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| public class RestartExample{
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(5000);
env.setStateBackend(new FsStateBackend("file:///xxx/project/bigdata-flink/checkpoint"));
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
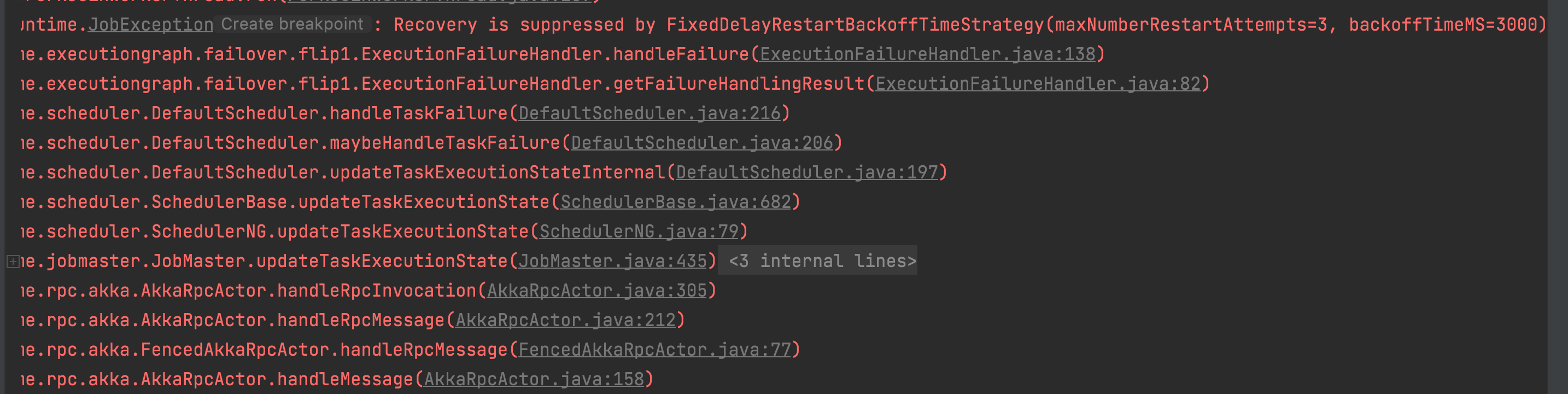
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.of(3, TimeUnit.SECONDS)));
// 连接kafka的配置参数
Properties kafkaProperties = new Properties();
kafkaProperties.setProperty("bootstrap.servers", "localhost:9092");
kafkaProperties.setProperty("group.id", "wordcount-demo");
kafkaProperties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
kafkaProperties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
kafkaProperties.setProperty("auto.offset.reset", "earliest");
kafkaProperties.setProperty("enable.auto.commit", "false");
//默认消费value值 SimpleStringSchema 读取kafka中value
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<String>("flink-source", new SimpleStringSchema(), kafkaProperties);
DataStream kafkaStream = env.addSource(kafkaConsumer).setParallelism(1);
// 模拟异常
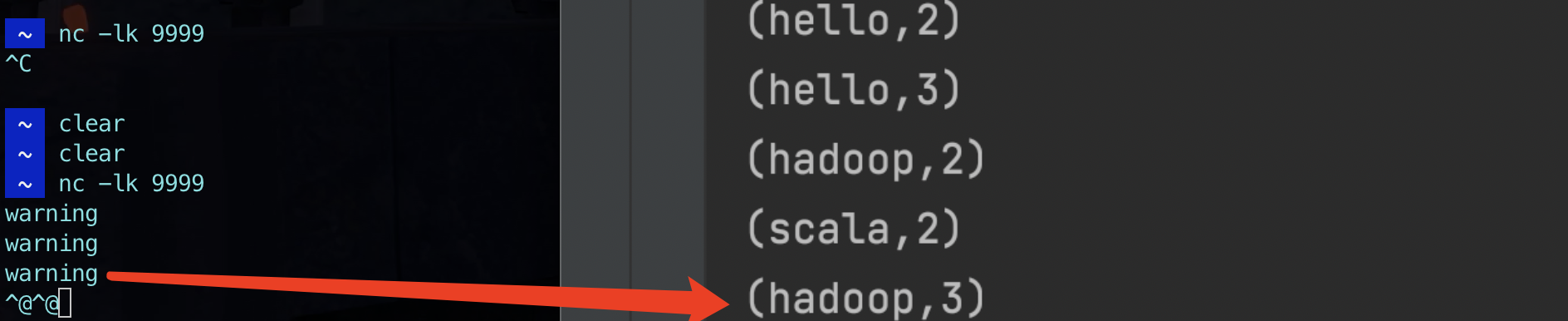
DataStream warningStream = env.socketTextStream("localhost", 9999);
warningStream.map(new MapFunction<String, String>() {
@Override
public String map(String s) throws Exception {
if (s.startsWith("warning")) {
throw new RuntimeException("error data");
} else {
return s;
}
}
}).print().setParallelism(1);
// wordcount
kafkaStream.map(new MapFunction<String, Tuple2<String,Integer>>() {
@Override
public Tuple2<String,Integer> map(String value) throws Exception {
return Tuple2.of(value,1);
}
}).keyBy(0).sum(1).print().setParallelism(1);
env.execute();
}
}
|
7. 遇到的问题#
- kafka 集群启动异常
1
| The Cluster ID xxx doesn't match stored clusterId Some(xxx) in meta.properties. The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong.
|
找到 kafka 配置文件 server.properties 中 log.dirs 的位置,将 meta.properties 中 cluster.id 配置修改为报错信息中提示的 Cluster ID xxx;修改好后重新启动。