1. 官网
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Introduction
2. 简介
2.1 分布式文件系统
分布式文件系统通过计算机网络连接大量节点,将不同节点的数据组织在一起,提供海量的数据存取能力。
2.2 HDFS是什么
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS relaxes a few POSIX requirements to enable streaming access to file system data. HDFS was originally built as infrastructure for the Apache Nutch web search engine project. HDFS is part of the Apache Hadoop Core project. The project URL is http://hadoop.apache.org/.
以上是 Hadoop 官网对 HDFS 的定义,简单来说,HDFS 是一个分布式文件系统,主要负责数据的存储,管理和容错处理。它的设计思想来源于 Google 的 GFS 文件系统(一个面向大规模数据密集型应用的、可伸缩的分布式文件系统)。
感兴趣的同学可以查看 GFS 论文:https://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf。
2.3 HDFS框架
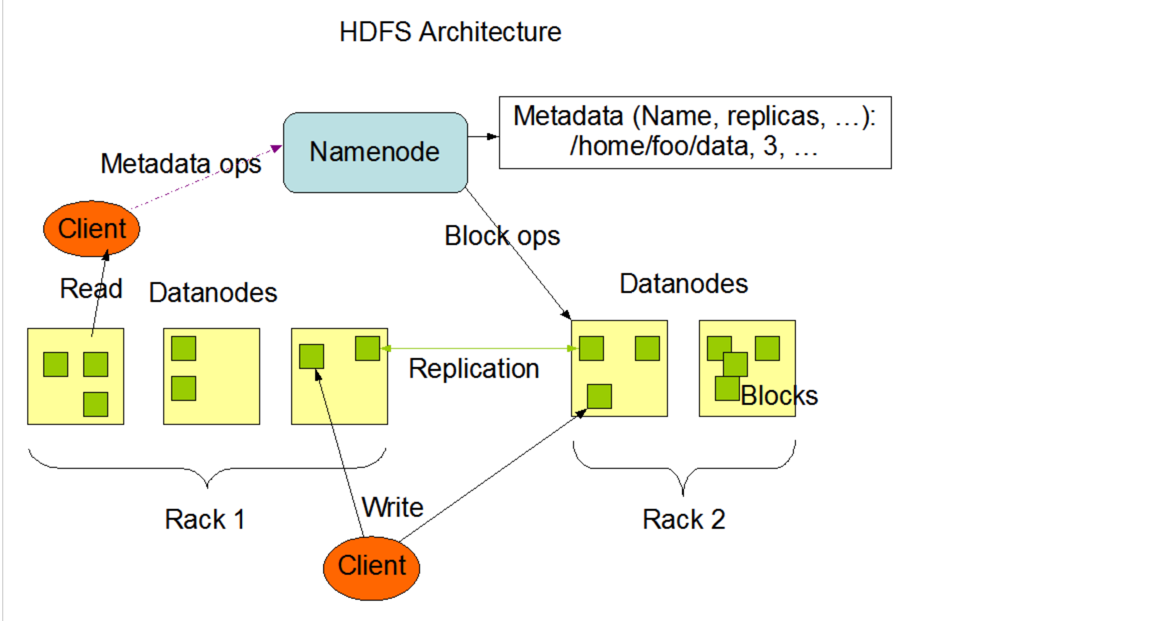
- NameNode
NameNode 是 HDFS 集群管理者,负责管理文件系统元信息和所有 DataNode。
1)管理元信息:NameNode 维护着整个文件系统的目录树,各个数据块信息等。
2)管理 DataNode:DataNode 周期性向 NameNode 汇报心跳以表明自己活着,一旦 NameNode 发现某个 DataNode 出现故障,会在其他存活 DataNode 上重构丢失的数据块。
一个 HDFS 集群中只存在一个对外服务的 NameNode,称为 Active NameNode ,为了防止单个 NameNode 出现故障后导致整个集群不可用,用户可启动一个备用 NameNode,称为 Standby NameNode,为了实现 NameNode HA(High Availability,高可用),需解决好两者的切换和状态同步问题。
1)主/备切换:HDFS 提供了手动方式和自动方式完成主备 NameNode 切换,手动方式是通过命令显示修改 NameNode 角色完成的,通常用于 NameNode 滚动升级。自动模式是通过 ZooKeeper 实现的,可在主 NamNode 不可用时,自动将备用 NameNode 提升为主 NameNode,以保证 HDFS 不间断对外提供服务。
2)状态同步:主/备 NameNode 并不是通过强一致协议保证状态一致的,而是通过第三方的共享存储系统。主 NameNode 将 EditLog(修改日志,比如创建和修改文件)写入共享存储系统,备用 NameNode 则从共享存储系统中读取这些修改日志,并重新执行这些操作,以保证与主 NameNode 的内存信息一致。
- DataNode
DataNode 存储实际的数据块,并周期性通过心跳向 NameNode 汇报自己的状态信息。
2.4 特性和局限性
- 特性
- 高容错:节点丢失,系统依然可用,数据保存多个副本,副本丢失后自动恢复。
- 大文件存储:HDFS 采用数据块的方式存储数据,将一个大文件切分成多个小文件,分布存储。
- 可构建在廉价的机器上:Hadoop 的设计对硬件要求低,无需构建在昂贵的高可用性机器上,实现线性扩展(随着节点数量的增加,集群的存储能力,计算能力随之增加)。
- 高数据吞吐量:HDFS 采用的是“一次写入,多次读取”这种简单的数据一致性模型,在HDFS中,一个文件一旦经过创建、写入、关闭后,一旦写入就不能进行修改了,只能进行追加,这样保证了数据的一致性,也有利于提高吞吐量。
2.局限性
- 不适合低延迟的数据访问:HDFS 是为了处理大型数据集,主要是为了达到高的数据吞吐量而设计,这就可能以高延迟作为代价。
- 不适合大量的小文件存储:NameNode 节点在内存中存储整个文件系统的元数据,因此文件的数量就会受到限制,每个文件的元数据大约 150 字节。
- 不适合并发写入:HDFS 目前不支持并发多用户的写操作,写操作只能在文件末尾追加数据。
2.5 可访问性
HDFS 给应用提供了多种访问方式。用户可以通过 Java API 接口访问,也可以通过 C语言 的封装 API 访问,还可以通过浏览器的方式访问 HDFS 中的文件。
- FS Shell
| |
- DFSAdmin
DFSAdmin 命令用来管理 HDFS 集群。这些命令只有 HDFS 的管理员才能使用。
| |
- 浏览器接口
3. 经验
- HDFS 横向扩容的时候,Re-balance 可能会很慢,有可能会影响业务端的读取,甚至会造成灾难性的影响,集群部分节点不可用(硬盘满了)甚至服务不可用。
- 受限于 NameNode 内存的大小,所以整个集群能存储的文件数量是有上限的,最好人为控制文件数量在合理的范围,否则会影响表数据的读写或者导致 NameNode 挂掉。
- HDFS 对数据的冷热分层和成本控制不是十分友好。
- 存储成本相对于对象存储较高。
- HDFS 对存算分离架构不友好。